Parallelization¶
There are two methods of parallelization implemented:
- shared memory (threading)
- distributed memory (multiprocessing)
Either of these methods can be used to split up each frame across the specified
number of workers. To specify the number of workers, use the -w N flag where
N is an integer greater than 0. By default, the application runs
multi-thread. To use multi-processing, pass the -mp flag. As an example, to
process a *.trak file using 4 workers and multi-processing use:
tracker -w 4 -mp path/to/video1.trak
Warning
Multiprocessing on Windows does not work due to issues between python’s multiprocessing library and OpenCV.
The basic parallelization technique is:
- The frame splitting routine tries to split the frame into equal “tiles” as close to squares as possible.
- Create the workers (either threads or processes) for each tile range.
- In the main thread, read the next frame and create a shared memory object.
- Tell each worker to process their tile.
- While waiting for the workers, in the main thread, read the next frame and create a shared memory object.
- Wait for all workers to finish.
- If running with the GUI, collect data from workers and display. This step is is expensive (moving lots of data). To avoid, run without the GUI. See Without the Graphical User Interface
- Go back to step 4 until all frames have been processed.
- Collect the tracks from all workers
Note
Tracks are not exchanged between workers because this data transfer is expensive and drastically slows down the processing with very little gain in track counts.
Test Case: SSCP July 17, 2012, 4Umf Run 1¶
Using the fist 100 frames (resolution of 1280x800) of the small scale challenge problem (SSCP) 4Umf Run 1 video on a Dell Precision 9710 with an Intel Xeon E5-2667 v4 running at 3.2GHz with 32 cores and 188.7GB of RAM, the following scaling was obtained:
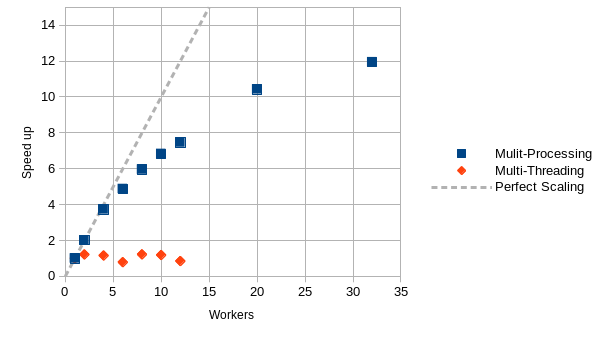
Where:
When using multiprocessing (-mp flag), the speed up increases linearly up to 4 workers. After 4 workers, the performance starts to decrease.
However, for multithreading (without the -mp flag), the performance gain is poor because of Python’s global interpreter lock (GIL) only allowing one thread to execute at a time.
Since tracks are not passed between workers to improve the performance of the processing, some velocity measurements could be lost. However, this loss of velocity measurements is insignificant. Even using 32 workers, 93% of the single worker velocity measurements are captured:
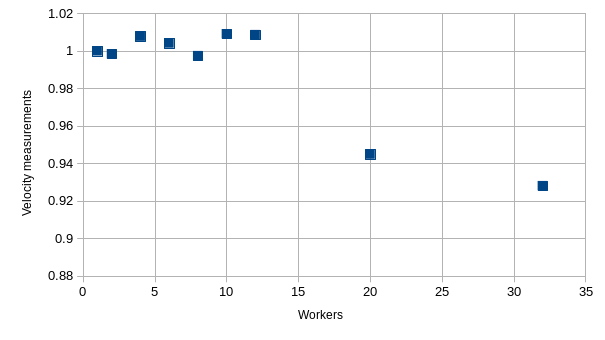
Where:
Note
For maximum performance, use the same number of workers as cores, use
multiprocessing (-mp flag) and without the GUI (-ng flag).