Response Surface¶
After the full model has been run and the responses collected at the sampled points, the
responses can be interpolated into a Response Surface. The response surface maps
continuouos input parameters into a continuous (or at least piece-wise continuous)
output (response), thus acting as a surrogate model for the full model evaluation.
The basic functionality of the Response Surface node is outlined below and used
extensively in the Examples.
Data¶
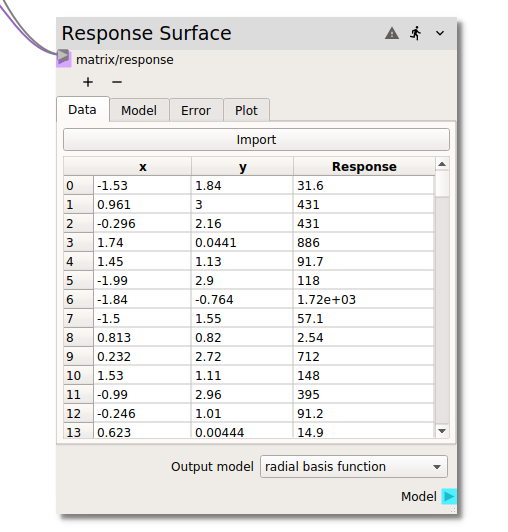
In the Data tab the required parameter input and corresponding full model response values
are entered into the node for the construction of the response surface. There are two ways in
which the required data can be input. In a typical workflow, the input matrix (typically from
a Design of Experiments node) and the corresponding model response (typically from
a code node) are connected to the matrix/response terminal as shown in the figure above.
Alternatively, if the data has been generated externally or exported from Nodeworks nodes and
agglomerated into a single table, the Import button at the top of the table can be used to
read in a csv file.
Once the input and response data has been loaded into the Data tab,
it can be sorted by individual input variables or the (full model) Response. The table can
be returned to the original index valued order by right clicking and selecting clear sort.
The right click menu also offers the capability to Exclude or Include specific
entries.
Model¶
There are several response surface modeling choices available in the Model tab drawing from
the scikits-learn and scipy libraries. Current modeling options include:
- gaussian process
- polynomial
- multilayer perceptron
- support vector machine
- decision tree
- random forest
- nearest
- linear
- cubic
- radial basis function
- MARS
With so many different modeling options, determining which particular model is best, or even
which sub-options of a given model are best, can be a challenging task. Several features within
the Response Surface node have been included to help with model selection.
The following section covers the Error tab which provides graphical representation
of the surrogate model error, i.e., the difference between actual (full) model response
and the response surface at the corresponding input values. The table of the Model
shows several quantitative RSM Error Metrics:
MSE- Mean Squared ErrorR^2- R squaredL_inf- L_infinity normL_1- L_2 normL_2- L_2 norm
The error metrics opperate on either the full dataset or the out-of-sample subset for
cross validation.
In cross validation, a subset of the dataset is witheld from the fitting of the
response surface. By default, 10 percent of the dataset is witheld as
Cross validation points. When cross validation is active, the RSM Error Metrics:
only apply to the witheld points. Without cross validation, the RSM Error Metrics:
apply to the whole dataset.
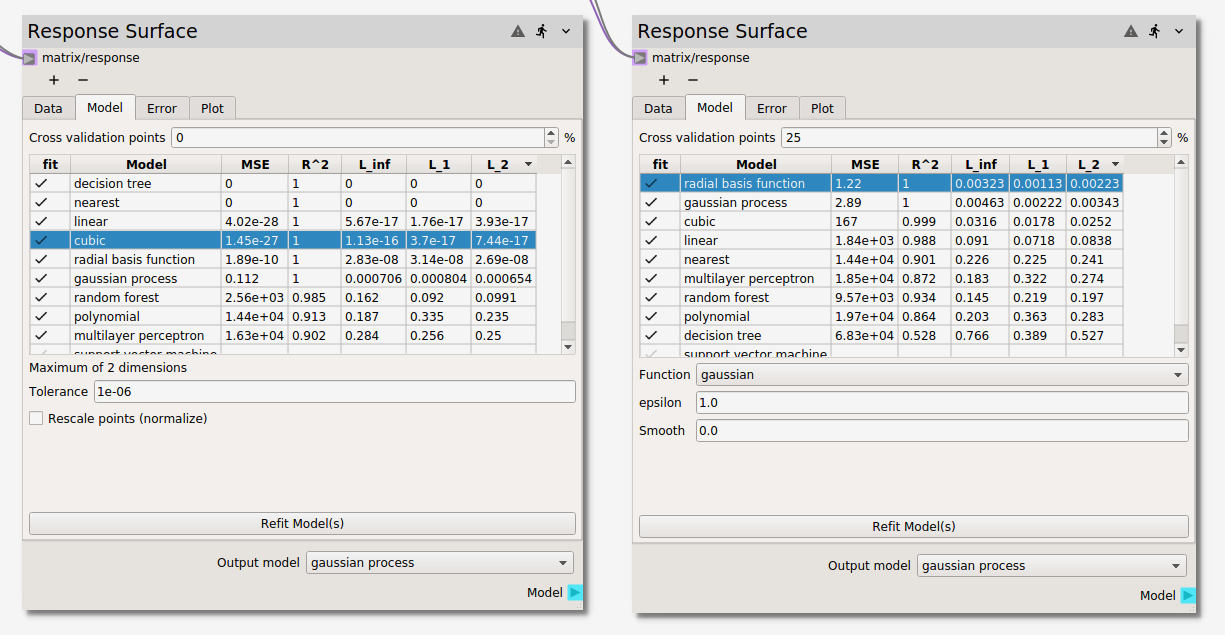
The figure above shows several Model surrogate candidates
without cross validation on the left and with 25% cross validation on the right. Without cross
validation four models show zero error (to double precision). However, these interpolators are
designed agree with the model at the sampled points. But how do these surrogates perform over
the entire design space, i.e., in between the sampled points? One way to test this is with
cross validation. When the models are fit to only 75%, we see that the radial basis function
(RBF) and gaussian process (GP) models have
better predictive accuracy of the 25% hold out data. The cross validation points can also be
used to fine tune model parameters. After activating new models or changing model options, the
error metrocs can be reassessed by hitting the Refit Model(s) button. The Refit Model(s)
button can also be used without changing any modeling options to simply re-draw the
Cross validation points, which are drawn at random from the full data set.
Error¶
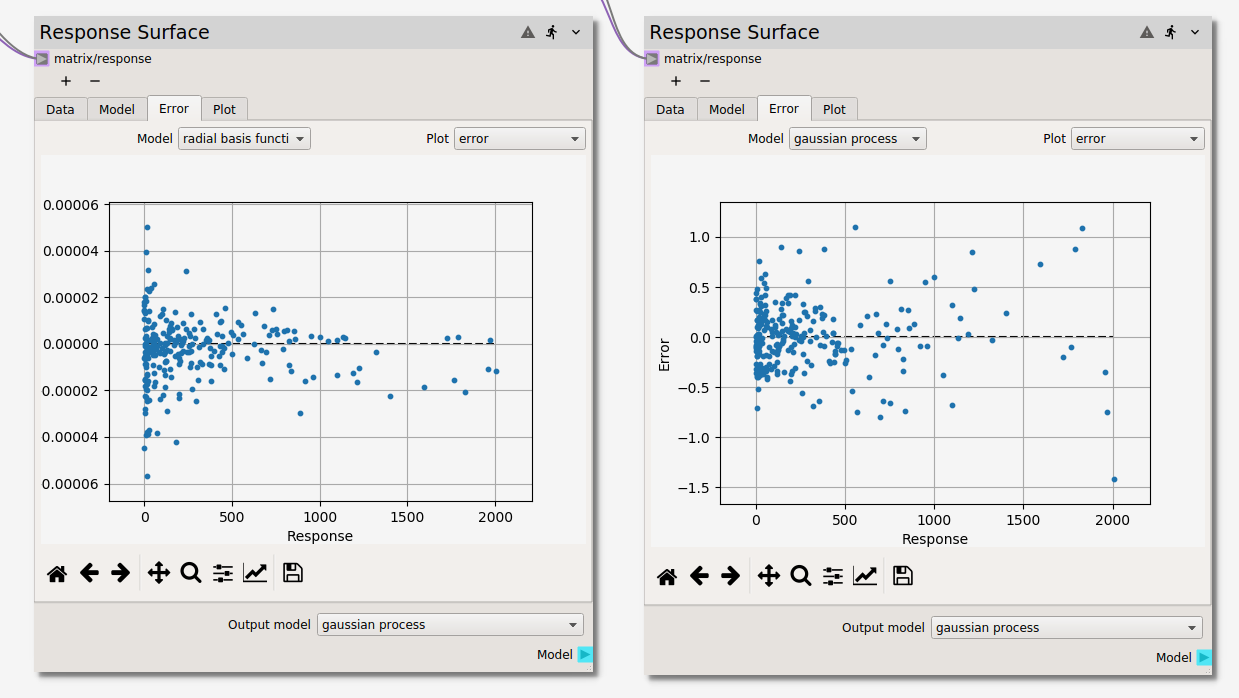
The difference between the surrogate model(s) and the data is visualized in the
Error tab. If more than one surrogate model has been fit, they can be selected
from the Model dropdown menu. The discrepancy for a given model can be viewed
in three different forms selectable from the Plot dropdown menu:
parityploterrorplot- error
histogram
As in the Plot tab of this and the Design of Experiments nodes, points can be highlighed
by holding select and dragging the cursor. Highlighted points can be excluded
(and included if prevously excluded) from the fit of the response surface models.
Warning
After assessing the performance of different surrogate models with the
RSM Error Metrics: and the Error plots, make sure to
return to the Model tab, set the Cross validation points to 0
and hit the Refit Model(s) button to re-fit the surrogate to the
full dataset before use in downstream analysis nodes.
Plot¶
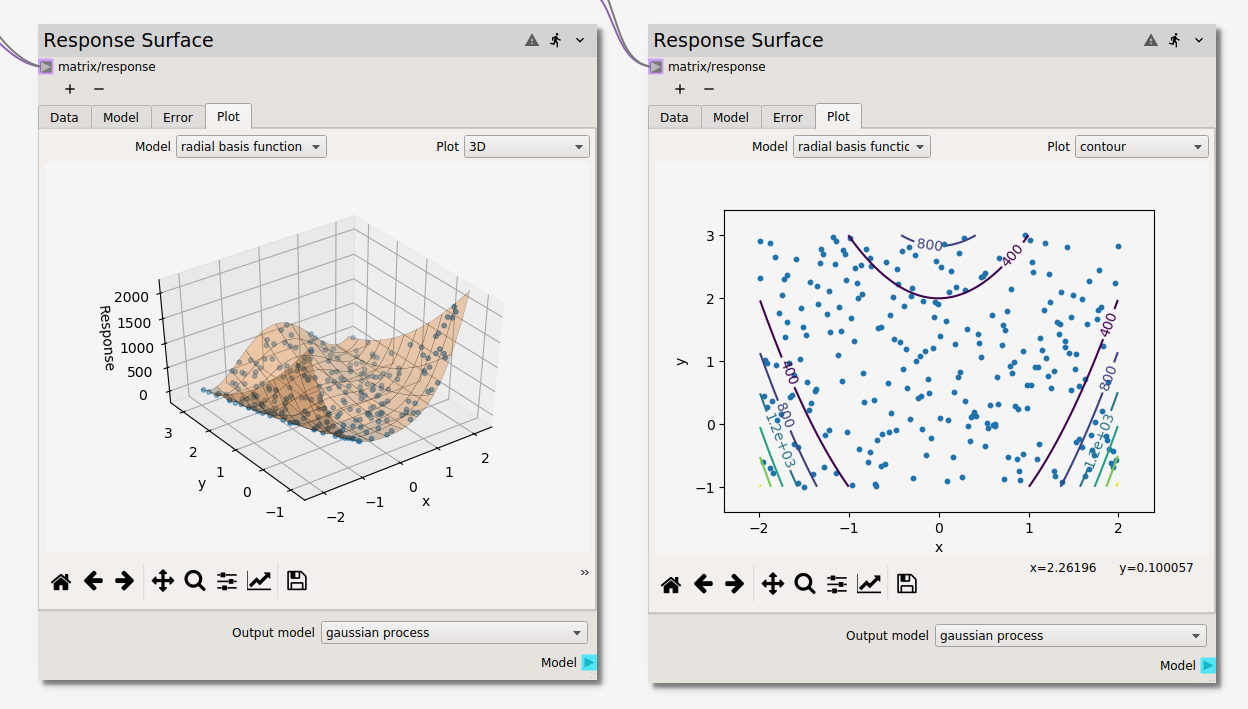
The different models can be visualized in either 3D or as a contour plot,
as shown below, in the Plot tab. If more than two input variables are used, the
variables used for the X Axis and Y Axis become selectable from dropdown
menus below the plot. Response data points are selectable and can be excluded from
the fit or shown in the Data table from the right click menu.
Output¶
Located at the bottom of the node below all of the tabs is the Output model selection.
If the models become computationally intensive, it is recommended that all but the desired
model be deselected from the Model tab. However, if it is desired to use more than one
surrogate model for analysis in downstream nodes, the different models can be toggled with
the Output model dropdown.