Design of Experiments¶
The Design of Experiments is used to choose the sampling points to be used as
input parameters for full model evaluation. It is important in this stage to
consider the potential range of interest and ensure that the sampling space
completely covers this range so that the resulting surrogate model is analyzed
within its range of support.
Variables¶
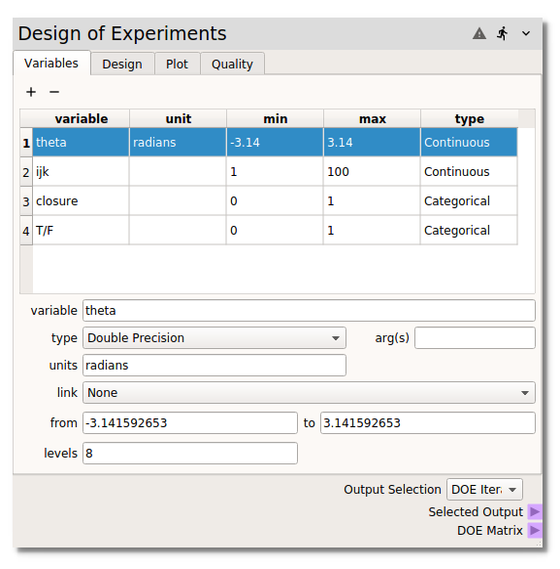
Variables are added in the first Variables tab by clicking on the  symbol
above the table. Variables can be removed from the table by highlighting them in the
table and clicking on the
symbol
above the table. Variables can be removed from the table by highlighting them in the
table and clicking on the  symbol. Information about the variable properties are entered
and edited in the entry spaces below the table. Some of the properties are
symbol. Information about the variable properties are entered
and edited in the entry spaces below the table. Some of the properties are type specific,
discussed below. All entered variables are listed and summarized in the table.
Variable properties:
variable: used to name and identify the variables.arg(s): defines the variable arguement, i.e., the ineger index if the variable is an array or vector.units: specify variable units for plotting.type:Double Precisionreal variables.
linkused to specify the variable as a function of another variable. NOTE that the variable is no longer an indpendent variable, which can be important when sampling randomly. However, it can also be useful when dependent variables need to be set consistenly with one independent random variable. The plot below shows a two variable array which must sum to one like the volume fraction of a two-phase mixture, for example.from: lower bound of parameter space of this variable dimension.to: upper bound of parameter space of this variable dimension.levels: defines the number of evenly spaced sampling points betweenfromandtoinclusively. NOTE that this is only used in the specific instance when the factorial design is specified on theDesigntab and theUse variable specific levelsoption is checked.
type:Integerinteger valued variables have the same properties asDouble Precisionvariables. NOTE that integers are also treated the same as reals during the calculation of the sampling points and then rounded. Care should be taken to avoid unwanted repeated samples.type:Stringtext based variables can be added and removed with the+and-symbols, activated by checking the box and named by double clicking on the entry space to the right of the checkbox. NOTE that the functionality ofStringvariables is not currently fully implemented. Specifically, downstream nodes can not handle string variables. Currently, it is recommended that users convert strings into integer or real variables.type:Logicalvariables only take integer values of 1 or 0 for True or False.
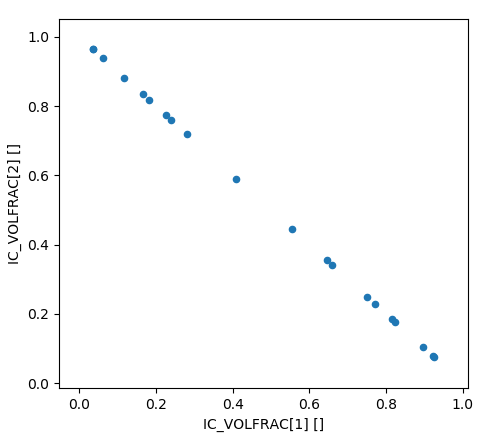
A design where two variables are linked.
Design¶
The Design tab is where the samples are actually constructed. Generally speaking, there
are four ways to construct a sampling scheme: ordered, sequentially (sub-random),
pseudo-randomly and simply importing a design constructed previously or from a different code.
Available Method’s include
Ordered designs:
Sequential designs
Random designs
Previously generated designs
- The
Importbutton is used to load a design saved locally incsv, comma separated variable format
Additional sampling properties:
Samplesspecifies the total number of samples drawnRepeatspecifies how many samples are repeated a specified number of times–this can be useful when generating designs for actual experiments and for non-deterministic simulationsRandomize sample order–this applies to the table as well as the order in which the samples are transferred to downstream nodesBuildgenerates the samples, also used to re-generate the design if properties are adjustedExportexports the samples to a comma separated variable file
Some other method-specific properties:
Randomizetoggles between setting the seed of the pseudorandom number generator from the givenseedor from the clock NOTE that randomize should be used with caution and the accepted design should be saved withExportas the design will be re-generated and changed when the sheet is runLevelsa constant number number of sampling intervals to be used with all variables with theFactorialdesign- Alternatively, users may check
Use variable specific levelsand the intervals for each variable are taken from thelevelsvalue entered previously in theVariablestabFacein thecentral compositedesign specifiescircumscribed,inscribedorfacedAlphain thecentral compositedesign specifiesorthogonalorrotatableOptimizein thelatin hypercubedesign allows selection of an optimization technique to improve the space filling of the design. See Latin Hypercube for more.Iterationsin thelatin hypercubedesign allows for the specification of iterations used by theOptimizetechnique.
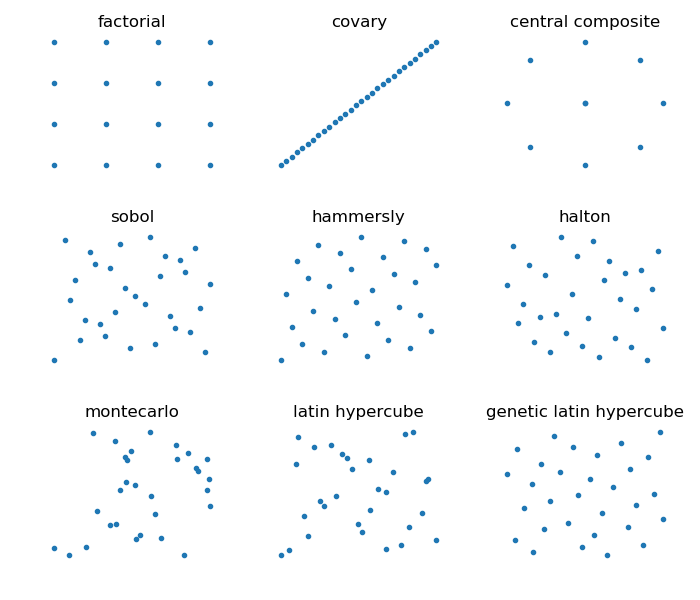
Example of designs with 30 samples.
Plot¶
The samples are plotted in a 2D scatter plot. The variables can be set by selecting the
Y Axis and X Axis variables from the dropdown list. The plot can be customized
and saved using the buttons below the plot. By default, all variables are shown with included
points in blue and excluded points in red. Excluded and/or included points can be
alternatively turned off by right clicking on the plot and unchecking.
Quality¶
The Quality tab analyzes the spatial quality of the design. The Minimum Distance,
Maximum Distance and their Ratio (Max/Min) are reported and calculated using
scipy.spatial.distance.pdist.
Several Distance Metric options are available from the scipy library:
The L2-Discrepancy from Eq.5 of [Fang2001] is also calculated for the
design.
References¶
| [Fang2001] | K.T. Fang and C.X. Ma, “Wrap-Around L2-Discrepancy of Random Sampling, Latin Hypercube, and Uniform Designs,” Journal of Complexity, vol. 17, pp. 608-624, 2001. |